Similarity between the hadron collider trigger
and vision processing model organization: from High Energy
Physics to brain studies
Our system developed for high energy physics is an example
of solution for a specific case of the "Big Data" problem.
This solution is based on the organization of the
trigger in different levels of selections,
exploiting at low level parallelized,
dedicated hardware for an
extremely efficient pre-processing step.
This organization is similar to models of the
vision processing task performed by the brain.
We plan to study the possible impact of our
devices for neurophysiologic studies of the brain.
Understanding how the brain processes information
or how it communicates with the peripheral nervous
system could provide new potential applications,
new computational systems that emulate human skills
or exploit underlying principles for new forms of
general purpose computing.
Significant improvements could be gained in terms
of performance, fault tolerance, resilience or
energy consumption over traditional ICT approaches.
The use of the associative memory processor for
brain studies is particularly fascinating.
The most convincing models that try to validate
brain functioning hypotheses are extremely similar
to the real-time architectures developed for HEP.
A multilevel model seems appropriate to describe
the brain organization for image processing [1]:
"The brain works by dramatically reducing input
information by selecting for higher-level processing
and long-term storage only those input data that match
a particular set of memorized patterns.
The double constraint of finite computing power
and finite output bandwidth determines to a large
extent what type of information is found to be
meaningful or relevant and becomes part of higher
level processing and longer-term memory."
The AM pattern matching has demonstrated to be
able to play a key role in
high rate filtering/reduction tasks.
Pattern matching works as a "edge detector", as
can be seen from the Figure 1.
Simulations have shown the potential of the pattern
matching algorithm on static 2-D images.
We are implementing the algorithm on our technology
to extend its application to 3-D images and movies.
These studies could have an impact in the area of
medical imaging for real-time diagnosis and the study
of this possible application is part of the project program.
The computing power is still a limiting factor for some high
quality medical applications. High-resolution medical
image processing, for example,
demands enormous memory and computing power to
allow 3D processing in a limited time.
One example is lung cancer Computed Tomography (CT)
screenings that profits of Computer-aided detection (CAD)
of pulmonary lesions to reduce the diagnosis times and
the risks of errors.
Our technology could be an interesting accelerator
for such computations.
The Filtering Algorithm
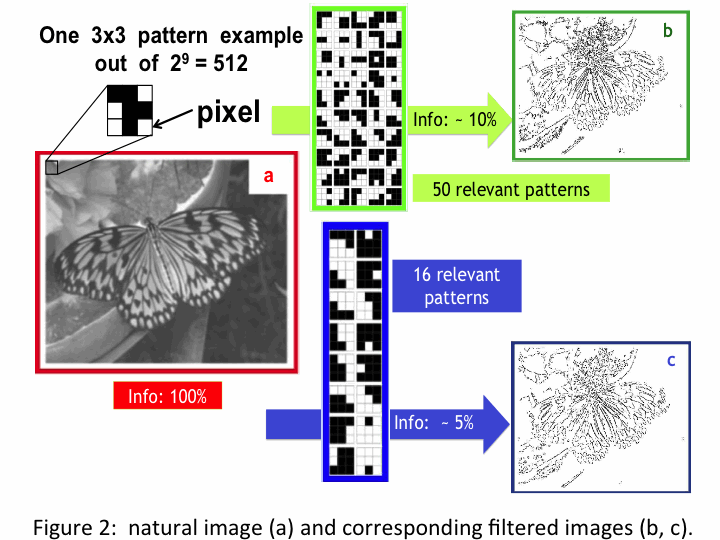 Figure 2 shows the results
of the simulations of the model described
in [1] where pattern matching with relevant
patterns is used to filter the main features of the image.
The pictures on the right (b,c) show the quality of the filtered images.
The butterfly can be clearly recognized even if the image information is
reduced at the level of 1/10 or less of the original content.
The associative memory works as an edge detector implementation
able to extract the salient features.
The pattern is defined as the collection of pixels contained in a 3x3
pixel square, as shown above the butterfly image (a) in Figure 2.
Each square is converted in a 9 bit sequence (each bit is 1 for a black
pixel and zero for a white one in the case of B/W)
or an 18 bit sequence in case of 4 level greys (2 bits/pixel).
The bit sequence is used to identify the pattern.
Starting from the left top corner the image is scanned by the 3x3
square that is moved in step of one pixel toward the right. When the
row is finished, the square is moved one pixel down to scan again the
raw from the left to the right. Each pattern detected in the figure during
the scan is compared to the set of "relevant patterns" predefined by a
training phase. It is rejected if it does not match any of them; it goes back
in its position in the picture if it is accepted. The Figure shows two collections
of relevant patterns for two different selections. The 16 patterns in the blue
box produce a larger reduction of information in the final image than the
50 patterns in the green box. Smaller is the set of chosen patterns stronger i
s the information reduction.
Analyzing 3-D images or movies increases enormously the number of possible
and relevant patterns. The pattern in this case is not a square, but a cube of pixels:
a set of three 3x3 squares taken from 3 subsequent frames. Each pattern for B/W is
made of 27 bits corresponding to 227 possible patterns. If 4 levels of grey are n
ecessary the total number of patterns becomes 2^54. One goal of the study
is to
understand which is the minimum set of "relevant patterns" in these
complex cases
and how much large has to be the memory to contain them.
Figure 2 shows the results
of the simulations of the model described
in [1] where pattern matching with relevant
patterns is used to filter the main features of the image.
The pictures on the right (b,c) show the quality of the filtered images.
The butterfly can be clearly recognized even if the image information is
reduced at the level of 1/10 or less of the original content.
The associative memory works as an edge detector implementation
able to extract the salient features.
The pattern is defined as the collection of pixels contained in a 3x3
pixel square, as shown above the butterfly image (a) in Figure 2.
Each square is converted in a 9 bit sequence (each bit is 1 for a black
pixel and zero for a white one in the case of B/W)
or an 18 bit sequence in case of 4 level greys (2 bits/pixel).
The bit sequence is used to identify the pattern.
Starting from the left top corner the image is scanned by the 3x3
square that is moved in step of one pixel toward the right. When the
row is finished, the square is moved one pixel down to scan again the
raw from the left to the right. Each pattern detected in the figure during
the scan is compared to the set of "relevant patterns" predefined by a
training phase. It is rejected if it does not match any of them; it goes back
in its position in the picture if it is accepted. The Figure shows two collections
of relevant patterns for two different selections. The 16 patterns in the blue
box produce a larger reduction of information in the final image than the
50 patterns in the green box. Smaller is the set of chosen patterns stronger i
s the information reduction.
Analyzing 3-D images or movies increases enormously the number of possible
and relevant patterns. The pattern in this case is not a square, but a cube of pixels:
a set of three 3x3 squares taken from 3 subsequent frames. Each pattern for B/W is
made of 27 bits corresponding to 227 possible patterns. If 4 levels of grey are n
ecessary the total number of patterns becomes 2^54. One goal of the study
is to
understand which is the minimum set of "relevant patterns" in these
complex cases
and how much large has to be the memory to contain them.
Implementation
Our initial plan was the use of exactly the same hardware developed
for HEP, adapted for generic imaging. The VME solution is very powerful and offers
a lot of computational power but it is large (not portable) and requires a specific interface
(VME standard). It is not easy to use for every day applications.
For these reasons we decided to try a more modern, compact solution.
One of our key goals is the miniaturization of the system in new modern standards
with the objective to make the system suitable for an open range of applications
in which massive and parallel data processing makes the difference.
The new Control Board needs the following characteristics:
1) powerful FPGA (Field Programmable Gate Arrays) with large on-board memory,
2) Ethernet & PCI Express I/O,
3) handling (distribution and collection) of all AM chip serial links,
4) configuration and control of the AM pattern bank,
5) provision of extra functionality to complete the AM functions in real-time.
While the AM chip needs challenging developments, one of the advantages of the FPGA
imaging task is that boards already available on the market are powerful
enough to cover the above listed specifications.
New generation commercial FPGAs are already available
(e.g. Xilinx Ultrascale FPGAs) and will allow us to develop
the high performance embedded system required in parallel
with the development of the new generation AMchip.
Figure 3 shows the computing unit used today,
based on a Xilinx Ultrascale evaluation board.
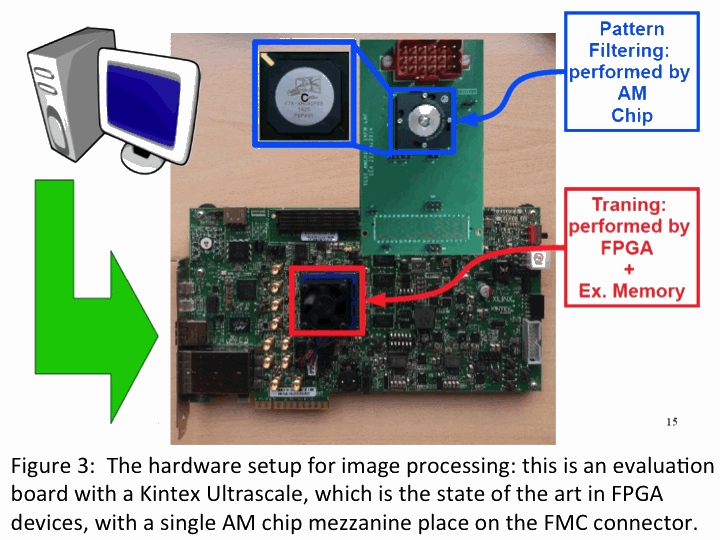 A new mezzanine with multiple AM chips can be connected
to the large connector on the top of the board,
but for the moment we start with a single chip
mezzanine as shown in Figure 3.
The algorithm is divided in two main parts:
"Training Phase" and the "Real-Time
patterns recognition phase" what we call the
"Data taking phase".
Most of the functions are executed by the FPGA
with the only exception of the
"Real-time patterns matching phase" that is executed by the associative memory.
A challenging task of the
implementation is the "Training Phase".
It is subdivided in the following steps:
A new mezzanine with multiple AM chips can be connected
to the large connector on the top of the board,
but for the moment we start with a single chip
mezzanine as shown in Figure 3.
The algorithm is divided in two main parts:
"Training Phase" and the "Real-Time
patterns recognition phase" what we call the
"Data taking phase".
Most of the functions are executed by the FPGA
with the only exception of the
"Real-time patterns matching phase" that is executed by the associative memory.
A challenging task of the
implementation is the "Training Phase".
It is subdivided in the following steps:
1. Calculation of the pattern
appearance frequencies:
The embedded system receives the image bit-streams
(e.g., data from a PC or a video camera).
The FPGA partitions/reorganizes the input data into the small
3x3 pixel patterns. Then, for each pattern,
the FPGA calculates the occurrence frequency in the processed
images/frames.
This calculation is iterated for all possible patterns
in a large set of training images.
In this way, different Probability Density Histograms (PDHs)
are computed for different training image sets.
PDHs are different for different types of images,
from different applications and sources.
Medical images have different PDHs than natural images,
security images etc. The training is required for the choice
of relevant patterns. When the environment and the lighting
conditions change, especially for security and machine vision
applications for streaming video the training has to be executed
continously in real-time. In this way the device adapts itself
autonomously to the different conditions of the images that it observes.
2.Pattern selection: the system must decide which set
of patterns must be selected for memory storage (the relevant patterns).
To maximize the capability to recognize shapes
(both human-brain recognition and artificial recognition),
we adopt the hypothesis described in [1],
i.e., the principle that maximum entropy is a measure of optimization.
The set of patterns that produces the largest amount of entropy
allowed by system limitations is the best set of patterns that
we can select to filter our images or videos. The system limitations can be
summarized in two main parameters:
N maximum number of storable patterns, and W, maximum bandwidth.
In [1] are described the details of the selection.
3.Pattern writing operation:
the relevant patterns (selected in step
2)
are written in the AMchip bank.
The writing operation is made via JTAG
by means of a system controller.
This is the last step of the Training Phase.
When the training is complete, the real-time pattern
matching phase or data taking can start:
the system is able
to work in real-time at the maximum frequency and is able to perform:
1. Parallel recognition of patterns in the data stream:
input patterns are sent to the AM bank and addresses of
matched patterns are transferred at the output of the AM chips.
2. Output formatting operation:
matched patterns are reorganized into a new image,
to produce the filtered images/videos, called "ketches"
where only the boundaries of the relevant objects appears,
while uniform areas are suppressed.
Logic Description
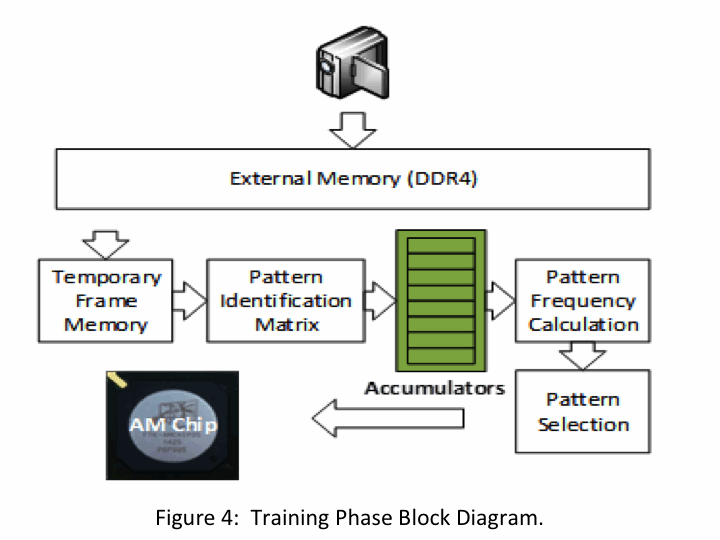 Figure 4 shows the block diagram representing the whole
algorithm implementation. The Training Phase is the most
time consuming part of the algorithm, so particular care
has been used to optimize its implementation and minimize
its execution time.
The system needs to be able to perform both training
and pattern identification in real-time for
demanding streaming video applications.
Several optimization techniques are used to achieve
the best performance possible in the hardware implementation.
The videoframes are stored in the external memory before
being transferred in an internal frame buffer.
As soon as enough data has been tranfered for the
3x3 patterns to be formed, a pattern identification
matrix begins to be loaded that identifies and
propagates two patterns per clock cycle to the pattern
accumulators. The accumulators are designed to
facilitate successive accumulation in the same memory
location ("all through" data logic).
As soon as the whole image sample has been read, the pattern frequency is
calculated by taking advantage the FPGA DSP slices.
The pattern selection process is done by using logic
with principle similar to the one used for pattern
identification in the HEP FTK implementation,
but appropriately optimized for image processing applications.
The selected patterns are then loaded to the AM chips for
the execution of the pattern matching process.
The prototype of the system is being developed on a last
generation FPGA device, a Xilinx Kintex Ultrascale XCKU040
using the KCU105 evaluation board.
Figure 4 shows the block diagram representing the whole
algorithm implementation. The Training Phase is the most
time consuming part of the algorithm, so particular care
has been used to optimize its implementation and minimize
its execution time.
The system needs to be able to perform both training
and pattern identification in real-time for
demanding streaming video applications.
Several optimization techniques are used to achieve
the best performance possible in the hardware implementation.
The videoframes are stored in the external memory before
being transferred in an internal frame buffer.
As soon as enough data has been tranfered for the
3x3 patterns to be formed, a pattern identification
matrix begins to be loaded that identifies and
propagates two patterns per clock cycle to the pattern
accumulators. The accumulators are designed to
facilitate successive accumulation in the same memory
location ("all through" data logic).
As soon as the whole image sample has been read, the pattern frequency is
calculated by taking advantage the FPGA DSP slices.
The pattern selection process is done by using logic
with principle similar to the one used for pattern
identification in the HEP FTK implementation,
but appropriately optimized for image processing applications.
The selected patterns are then loaded to the AM chips for
the execution of the pattern matching process.
The prototype of the system is being developed on a last
generation FPGA device, a Xilinx Kintex Ultrascale XCKU040
using the KCU105 evaluation board.
Reconstruction of contours
The extracted features can be processed with fast but complex reconstruction
algorithms implemented on FPGA devices as we do in the FTK project to find
clusters of contiguous pixels
above a certain programmable threshold [2]. As we process them producing
measurements that characterize their shape, we can measure quantities of
interest in medical applications like the size of the found spots, how circular or
irregular the spot is. The algorithm can be extended to 3-D images.
Lung cancer diagnosis: an interesting example application
A lung cancer Computed Tomography (CT) screening produces 300-400
noisy slices per subject to be reviewed (Fig. 5). This is a huge amount
of difficult
work for radiologists. Computer-aided detection (CAD) of pulmonary lesions used
as second reader can improve the radiologists?detection ability. Nodules are identified
because of their sphericity, so a 3-D reconstruction could be particularly interesting
to distinguish them from vessels and bronchial tubes that have long shapes in the lung images.
We plan to try this 3-D reconstruction on our pattern matching machine.
[1] M. Del Viva, G. Punzi, and D. Benedetti. Information and perception of meaningful patterns.
PloS one 8.7 (2013):e69154.
[2] C.-L. Sotiropoulou, S. Gkaitatzis, A. Annovi, M. Beretta, P.
Giannetti,
K. Kordas, P. Luciano, S. Nikolaidis, C. Petridou and G. Volpi
"A Multi-Core FPGA-based 2D Clustering Implementation for Real Time
Image Processing", in IEEE Trans. on Nuclear Science, vol. 61, no. 6,
pp 3599 - 3606, December 2014.

